Zhiwei Han | 韩志伟
I am a final-year doctoral researcher in Machine Learning at the Technical University of Munich (TUM) and fortiss GmbH, under the supervision of PD. Dr. Habil. Hao Shen. I am currently seeking industry research internship opportunities in multi-modal and multi-view learning.
My research focuses on self-supervised multi-view and multi-modal learning, through the lens of disentanglement and identifiability. In parallel, I am actively involved in multiple federal- and state-funded industry research projects, leading to peer-reviewed publications across diverse application domains. Before my doctoral research, I earned an M.Sc. in Electrical Engineering and Information Technology at TUM.
I am particularly interested in applications to vision–language learning and multimodal data analysis, where robustness, interpretability, and stable cross-modal alignment are critical.

News
-
[Ongoing] One paper in preparation for UAI 2026.
-
[Jan., 2026] Our paper “Provable Affine Identifiability of Nonlinear CCA under Latent Distributional Priors” is accepted at AISTATS 2026!
-
[Jan., 2026] Our paper “Mechanistic Independence: A Principle for Identifiable Disentangled Representations” is accepted at ICLR 2026!
Selected Publications
Abstract
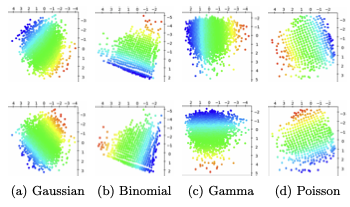
In this work, we establish conditions under which nonlinear CCA recovers the ground-truth latent factors up to an orthogonal transform after whitening. Building on the classical result that linear mappings maximize canonical correlations under Gaussian priors, we prove affine identifiability for a broad class of latent distributions in the population setting. Central to our proof is a reparameterization result that transports the analysis from observation space to source space, where identifiability becomes tractable. We further show that whitening is essential for ensuring boundedness and well-conditioning, thereby underpinning identifiability. Beyond the population setting, we prove that ridge-regularized empirical CCA converges to its population counterpart, transferring these guarantees to the finite-sample regime. Experiments on a controlled synthetic dataset and a rendered image dataset validate our theory and demonstrate the necessity of its assumptions through systematic ablations.

Abstract
Disentangled representations seek to recover latent factors of variation underlying observed data, yet their identifiability is still not fully understood. We introduce a unified framework in which disentanglement is achieved through mechanistic independence, which characterizes latent factors by how they act on observed variables rather than by their latent distribution. This perspective is invariant to changes of the latent density, even when such changes induce statistical dependencies among factors. Within this framework, we propose several related independence criteria -- ranging from support-based and sparsity-based to higher-order conditions -- and show that each yields identifiability of latent subspaces, even under nonlinear, non-invertible mixing. We further establish a hierarchy among these criteria and provide a graph-theoretic characterization of latent subspaces as connected components. Together, these results clarify the conditions under which disentangled representations can be identified without relying on statistical assumptions.
Abstract
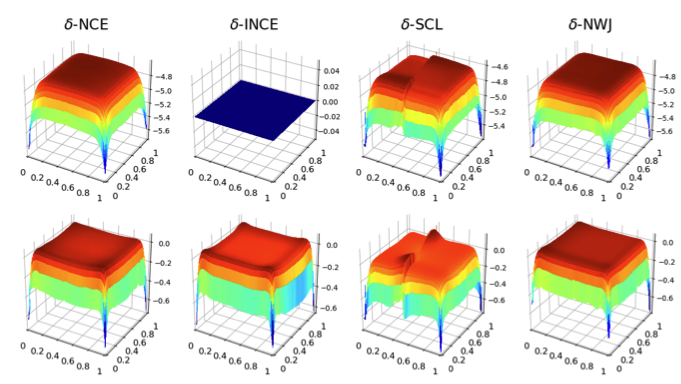
Contrastive learning has recently emerged as a promising approach for learning data representations that discover and disentangle the explanatory factors of the data. Previous analyses of such approaches have largely focused on individual contrastive losses, such as noise-contrastive estimation (NCE) and InfoNCE, and rely on specific assumptions about the data generating process. This paper extends the theoretical guarantees for disentanglement to a broader family of contrastive methods, while also relaxing the assumptions about the data distribution. Specifically, we prove identifiability of the true latents for four contrastive losses studied in this paper, without imposing common independence assumptions. The theoretical findings are validated on several benchmark datasets. Finally, practical limitations of these methods are also investigated.

Abstract
In this work, we present SymObjectRF, a symmetry-based method that learns object-centric representations for rigid objects from one dynamic scene without hand-crafted annotations. SymObjectRF learns the appearance and surface geometry of all dynamic object in their canonical poses and represents individual object within its canonical pose using a canonical object field (COF). SymObjectRF imposes group equivariance on rendering pipeline by transforming 3D point samples from world coordinate to object canonical poses. Subsequently, a permutation-invariant compositional renderer combines the color and density values queried from the learned COFs and reconstructs the input scene via volume rendering. SymObjectRF is then optimized by minimizing scene reconstruction loss. We show the feasibility of SymObjectRF in learning object-centric representations both theoretically and empirically.
Abstract
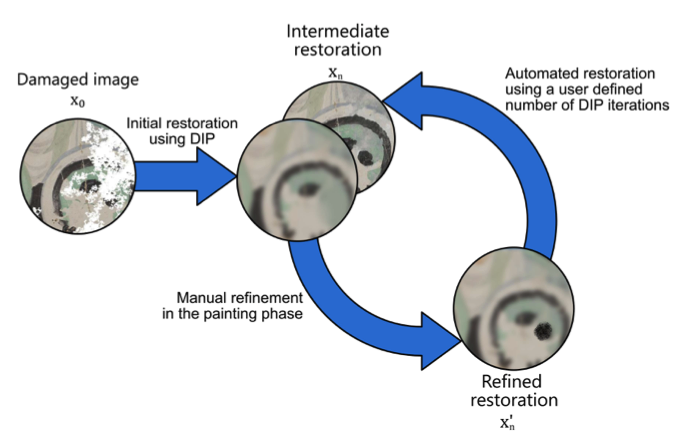
The purpose of image restoration is to recover the original state of damaged images. To overcome the disadvantages of the traditional, manual image restoration process, like the high time consumption and required domain knowledge, automatic inpainting methods have been developed. These methods, however, can have limitations for complex images and may require a lot of input data. To mitigate those, we present "interactive Deep Image Prior", a combination of manual and automated, Deep-Image-Prior-based restoration in the form of an interactive process with the human in the loop. In this process a human can iteratively embed knowledge to provide guidance and control for the automated inpainting process. For this purpose, we extended Deep Image Prior with a user interface which we subsequently analyzed in a user study. Our key question is whether the interactivity increases the restoration quality subjectively and objectively. Secondarily, we were also interested in how such a collaborative system is perceived by users.
Abstract
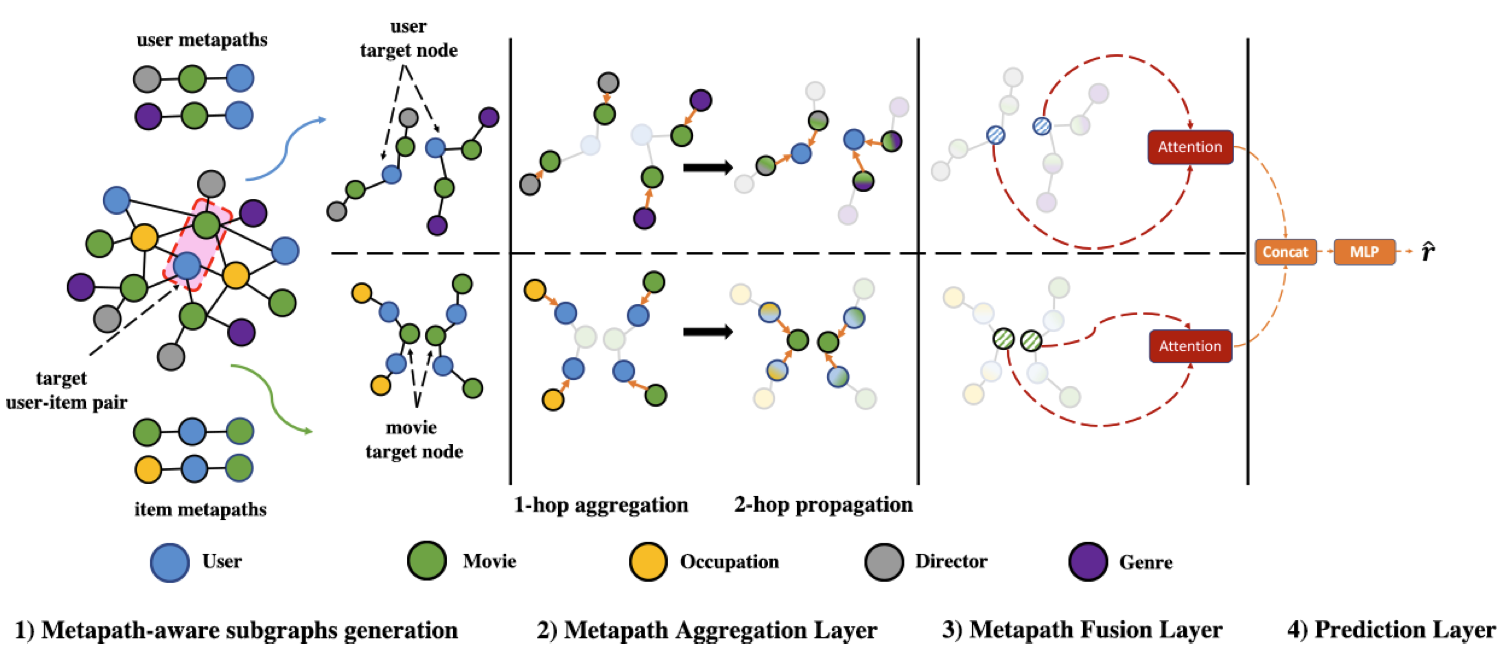
Due to the shallow structure, classic graph neural networks (GNNs) failed in modelling high-order graph structures that deliver critical insights of task relevant relations. The negligence of those insights lead to insufficient distillation of collaborative signals in recommender systems. In this paper, we propose PEAGNN, a unified GNN framework tailored for recommendation tasks, which is capable of exploiting the rich semantics in metapaths. PEAGNN trains multilayer GNNs to perform metapath-aware information aggregation on collaborative subgraphs, $h$-hop subgraphs around the target user-item pairs. After the attentive fusion of aggregated information from different metapaths, a graph-level representation is then extracted for matching score prediction. To leverage the local structure of collaborative subgraphs, we present entity-awareness that regularizes node embedding with the presence of features in a contrastive manner. Moreover, PEAGNN is compatible with the mainstream GNN structures such as GCN, GAT and GraphSage. The empirical analysis on three public datasets demonstrate that our model outperforms or is at least on par with other competitive baselines. Further analysis indicates that trained PEAGNN automatically derives meaningful metapath combinations from the given metapaths.
Teaching
-
Applied Reinforcement Learning (Winter Semester, 2022-2023)Role: Teaching Assistant (TA) · Chair of Data Processing · Technical University of Munich (TUM)
Projects
- Role & outcomes: Project and technical lead; delivered the project and published two peer-reviewed conference papers, including one Best Paper Award (FES 2023).
- Leadership: Led and coordinated a three-person research team across problem formulation, system design, and experimental validation.
- Research contribution: Designed and evaluated a battery scheduling algorithm leveraging household load forecasting and electricity market price prediction.
- System contribution: Developed a preference-aware peer-to-peer energy trading platform, integrating user preferences into decentralized market mechanisms.
- Role & outcomes: Co-lead researcher and technical contributor; two papers accepted at peer-reviewed NeurIPS and ICML workshops.
- Research contribution: Developed a few-shot stress detection framework based on self-supervised learned representations.
- Research contribution: Proposed and implemented a symmetry-constrained object-centric NeRF framework for 3D object-centric learning.
- Role & outcomes: Technical contributor; two papers accepted at peer-reviewed venues.
- Research contribution: Designed and evaluated a knowledge-augmented graph recommender system to mitigate cold-start by integrating structured side information.
- Research contribution: Implemented and evaluated a VAE-based unsupervised node representation learning approach to learn informative embeddings under sparse supervision.
- Role & outcomes: Technical contributor; one paper accepted at UMAP 2018.
- Research contribution: Built a proof of concept for AI-based IDE user preference prediction on AUTOFOKUS 3, combining behavioral signals with learned user representations.
All Publications
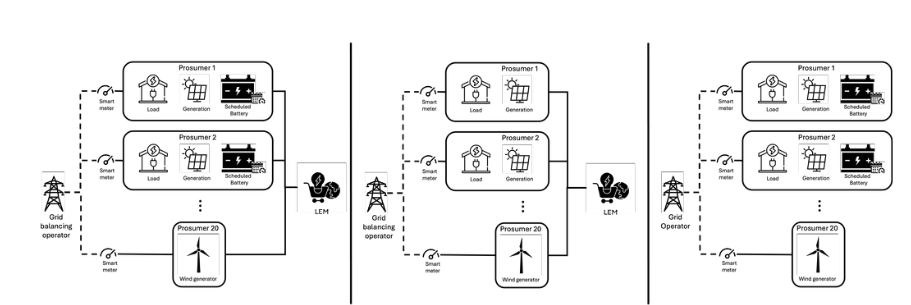
Abstract
Local energy markets (LEMs) provide an opportunity for prosumers to exchange their energy at the local grid level. Despite various studies on LEMs and their use in decentralizing the traditional top-down approach of electricity grids, there is still a lack of effective coordination and scheduling methods for energy trading. The concepts still lack ideas as regards how to effectively coordinate the markets and schedule the local devices for proper energy trading. In this work, we propose an open-source optimal scheduling model to enable local prosumers to effectively coordinate their devices for local energy trading. The proposed model was evaluated for its applicability in a German use case scenario. The simulation results show that the model can create a community self-sufficiency of up to 82% if properly coordinated and provide additional economic benefits to the local prosumers.
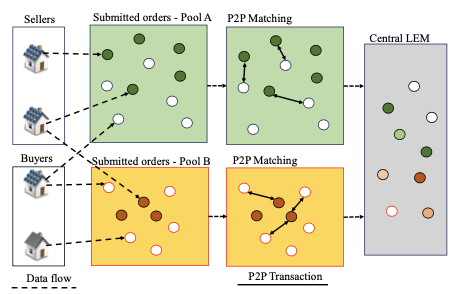
Abstract
Local energy markets (LEMs) have been introduced in the last few decades as a bottom-up approach solution to create a competitive market for prosumers/consumers to trade their energy and have control over their energy sources. However, there is still a gap in research for prosumers/consumers willing to exchange energy at defined price-and energy-preferences. In this work, we propose an open-source LEM model for matching prosumers and consumers with the same energy and price policy in a decentralized LEM. Our model was verified of its applicability by simulating it with the data from a German community. The simulation results showed that the model was able to satisfy the energy preferences of the consumers and prosumers in the local community to an average of more than 60%. Moreover, the model also demonstrated improved performance in terms of self-sufficiency and self-consumption ratio to the community compared to trading with the central LEM.
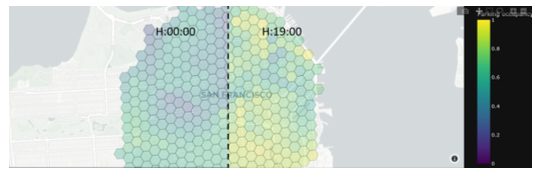
Abstract
This paper demonstrates a simulation framework that collects data about connected vehicles' locations and surroundings in a realistic traffic scenario. Our focus lies on the capability to detect parking spots and their occupancy status. We use this data to train machine learning models that predict parking occupancy levels of specific areas in the city center of San Francisco. By comparing their performance to a given ground truth, our results show that it is possible to use simulated connected vehicle data as a base for prototyping meaningful AI-based applications.
Abstract
In graph analysis community detection and node representation learning are two highly correlated tasks. In this work, we propose an efficient generative model called J-ENC for learning Joint Embedding for Node representation and Community detection. J-ENC learns a community-aware node representation, i.e., learning of the node embeddings are constrained in such a way that connected nodes are not only “closer” to each other but also share similar community assignments. This joint learning framework leverages community-aware node embeddings for better performance on these tasks: node classification, overlapping community detection and non-overlapping community detection. We demonstrate on several graph datasets that J-ENC effectively outperforms many competitive baselines on these tasks. Furthermore, we show that J-ENC not only has quite robust performance with varying hyperparameters but also is computationally efficient than its competitors.
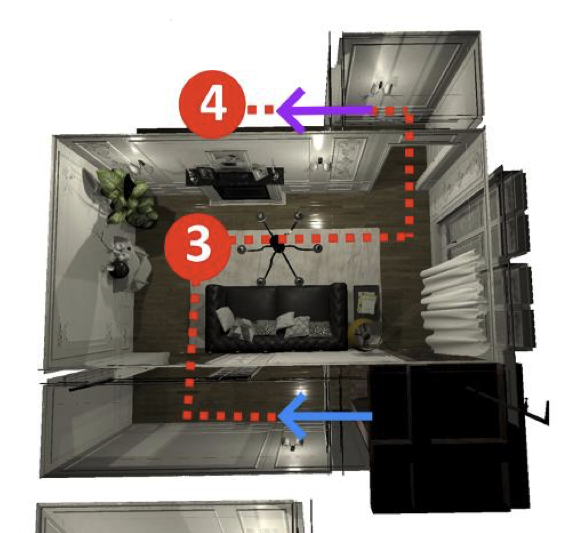
Abstract
Classifying stress in firefighters poses challenges, such as accurate personalized labeling, unobtrusive recording, and training of adequate models. Acquisition of labeled data and verification in cage mazes or during hot trainings is time consuming. Virtual Reality (VR) and Internet of Things (IoT) wearables provide new opportunities to create better stressors for firefighter missions through an immersive simulation. In this demo, we present a VR-based setup that enables to simulate firefighter missions to trigger and more easily record specific stress levels. The goal is to create labeled datasets for personalized multilevel stress detection models that include multiple biosignals, such as heart rate variability from electrocardiographic RR intervals. The multi-level stress setups can be configured, consisting of different levels of mental stressors. The demo shows how we established the recording of a baseline and virtual missions with varying challenge levels to create a personalized stress calibration.
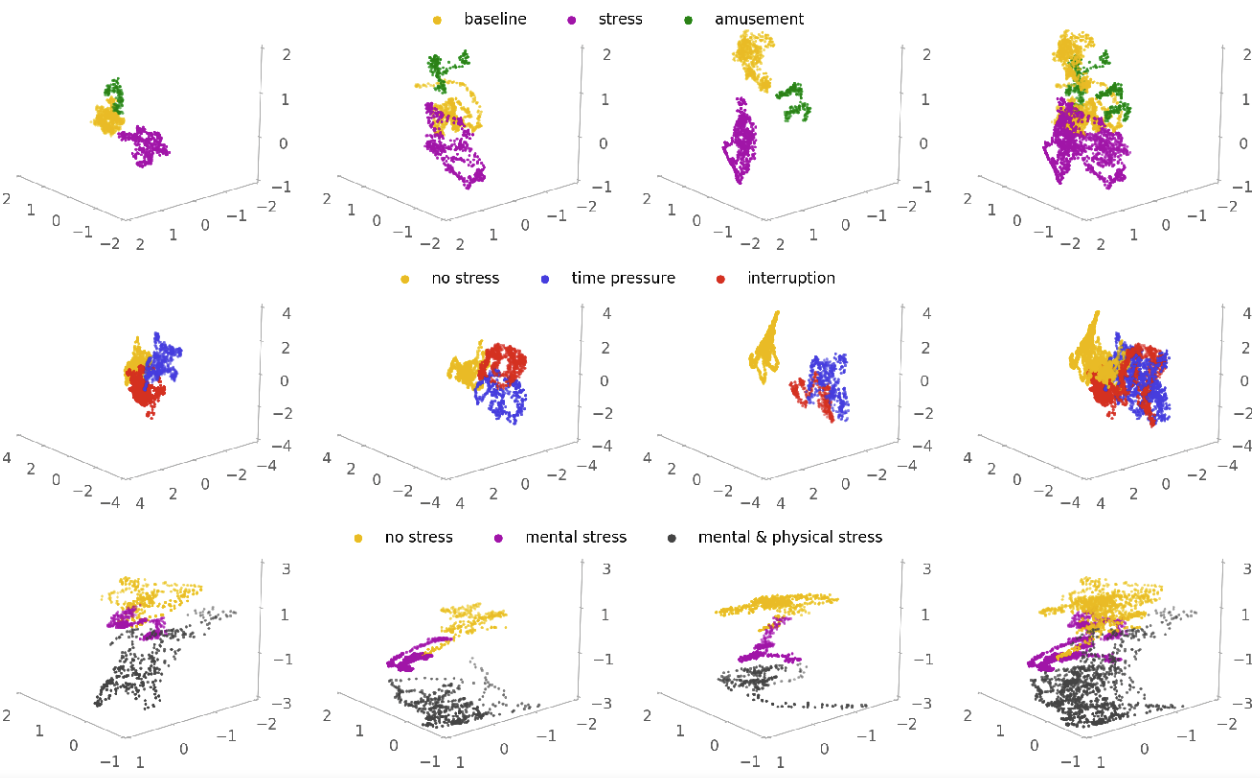
Abstract
Automated stress detection using physiological sensors is challenging due to inaccurate labeling and individual bias in the sensor data. Previous methods consider stress detection as a supervised classification task, where bad labeling leads to a large performance drop. Furthermore, the poor generalizability to unseen subjects reveals the importance of personalizing stress detection for both inter- and intra-individual sensor data vari- ability. Towards this end we present a label-free feature extractor and an efficient personalization method with the ”human in the loop” approach. First, we capture the intra-individual variability and encode it in self-supervised learned features, which are usually well separable and independent of noisy stress labels. Next, personalization is achieved by assigning labels to critical reference points via very few interactions between subject and wearable device. The promising results of the conducted experiments show the effectiveness and efficiency of our proposed method.
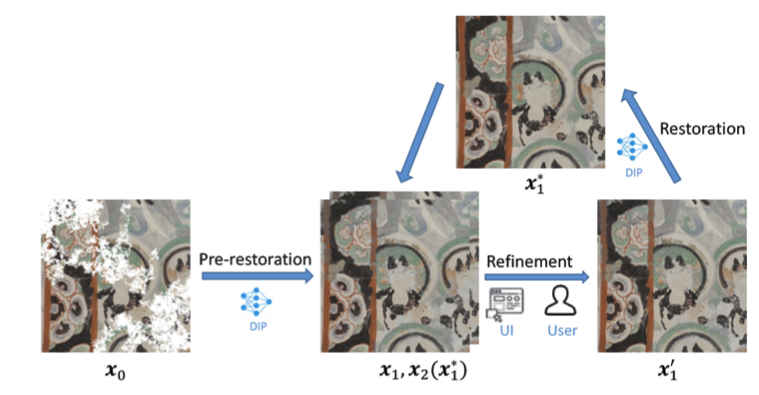
Abstract
Machine learning and many of its applications are considered hard to approach due to their complexity and lack of transparency. One mission of human-centric machine learning is to improve algorithm transparency and user satisfaction while ensuring an acceptable task accuracy. In this work, we present an interactive image restoration framework, which exploits both image prior and human painting knowledge in an iterative manner such that they can boost on each other. Additionally, in this system users can repeatedly get feedback of their interactions from the restoration progress. This informs the users about their impact on the restoration results, which leads to better sense of control, which can lead to greater trust and approachability. The positive results of both objective and subjective evaluation indicate that, our interactive approach positively contributes to the approachability of restoration algorithms in terms of algorithm performance and user experience.
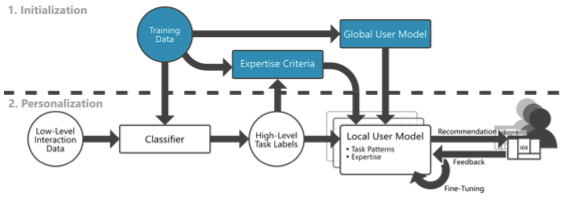
Abstract
Integrated Development Environments (IDEs) are used for a varietyof software development tasks. Their complexity makes them chal-lenging to use though, especially for less experienced developers. In this paper, we outline our approach for an user-adaptive IDE that is able to track the interactions, recognize the user's intent and expertise, and provide relevant, personalized recommendations in real-time. To obtain a user model and provide recommendations, interaction data is processed in a two-stage process: first, we derive a bandit based global model of general task patterns from a dataset of labeled interactions. Second, when the user is working with the IDE, we apply a pre-trained classifier in real-time to get task labels from the user's interactions. With those and user feedback we fine-tune a local copy of the global model. As a result, we obtain a personalized user model which provides user-specific recommendations. We finally present various approaches for using these recommendations to adapt the IDE's interface. Modifications range from visual highlighting to task automation, including explanatory feedback.